
Package Management
CMPR: Signs You’re a Level 2 in Package Maturity
This article is 2/5 in our series on Centrally Managed Package Repositories, also available as a chapter in our free, downloadable eBook Package Management at Scale
Due to the various approaches maturing organizations can take, it can be hard to assess yourself as Level 2, but if any of the following apply, you’re likely iterating within this stage.
By this stage, organizations are beginning to mature, having moved beyond the ad hoc chaos of Level 1. Teams have begun adopting internal registries or file shares, to share reusable libraries and modules more deliberately. Developers may perform license checks, use vulnerability scanners such as Snyk or npm audit, and even publish reusable artifacts for others within the organization.
However, these efforts remain fragmented. Each team manages its own tooling, workflows, and conventions. This decentralization results in misalignment and limited visibility. Internal packages are published but often go unnoticed, leading developers to reimplement existing functionality, wasting time and effort. Discovery relies on Slack threads, word of mouth, or outdated docs, frequently resulting in missed opportunities for reuse or worse, use of unmaintained code. CI/CD pipelines require manual configuration for team-specific registries or tools, increasing the risk of build failures, version mismatches, and production crashes. The outcome is a longer onboarding process, slower deliveries, and higher development costs.
This leads to a false sense of progress. While it may appear that the org is maturing, the lack of central oversight, shared standards, and unified tooling introduces new layers of complexity. What works for a small group of teams becomes unmanageable as the organization grows. Without proper governance, trust in internal packages erodes as duplication, unclear ownership, and inconsistent quality go unchecked, often without teams realizing better options already exist. Without visibility, incident response slows. And without standardization, scale becomes a liability, not a strength.
In this chapter, we’ll explore the challenges organizations encounter when packages are shared, but package management is not centralized, highlighting the resulting technical limitations and security blind spots that arise:
| Centralization | Minimal to nonexistent, as teams often operate isolated registries (e.g., NuGet Server, Verdaccio), with no centralized repository or shared infrastructure. |
| Governance | A lack of organization-wide enforcement and standardization leads developers to follow team-specific or personal rules. |
| Curation | Without formal approval workflows and pre-download controls, teams and individual developers will vet packages on an ad hoc basis. |
| Distribution | Platform and toolset fragmentation sees OSS and proprietary packages distributed informally through scattered registries and shared drives, with no clear provenance. |
| Scalability | Tool sprawl, duplicated packages, and a lack of visible structure make onboarding new teams and enforcing consistent practices difficult, limiting scalability. |
Developer Enablement: Team-Level Progress with Persistent Friction
The siloed adoption of lightweight package registries (think NuGet Server, Verdaccio, PyPI Server) limits internal package sharing to individual teams and technology stacks, without consistent structure and visibility.
⚠ Inefficient discovery and reuse: Without a central index or formal documentation, developers rely on tribal knowledge and message threads to find existing internal solutions, resulting in duplicated effort to rebuild similar functionality, and increased delivery time and costs.
⚠ Slowed collaboration: Each team adopts its own tooling, conventions, and registries, with no shared standards for naming, versioning, or publishing. Onboarding is slowed, as developers waste time learning unfamiliar tools, figuring out which internal packages to use, and adjusting to different workflows, leading to interpersonal friction, where new engineers are overwhelmed with learning, and leadership is frustrated with overexplaining.
⚠ Registry fragmentation creates friction: Redundant registries are spun up independently, per team or tech stack (e.g., multiple Maven proxies). Additionally, CI/CD pipelines and local environments require custom configuration to work with team-specific registries, increasing maintenance overhead, as costs spent on running multiple registry instances and servers accumulate.
⚠ Inconsistent quality and standards: No organization-wide rules exist to govern how packages are built, reviewed, and documented. This lack of consistency leads to wide variations in quality and usability, reducing trust and adoption of internal packages, leading developers to recreate, at the cost of the org’s time and financial resources, existing functionality.
⚠ Reinvention and wasted effort: Useful practices, tools, and solutions remain locked within teams, since there’s no shared platform or standard for cross-team sharing. Critical knowledge and valuable innovations aren’t surfaced, leading to repeated problem-solving and missed opportunities for leverage.
While efficient package management practices are emerging, they are localized within teams. The lack of coordination, formal transfer of critical knowledge, and tangibly enforced standardization leads to slowed development, decreased collaboration and package reuse, and increased workloads for engineers recreating existing functionality.
Security: Ad Hoc Scanning and Siloed Management
Basic security practices, such as running vulnerability scans via npm audit, dotnet list package –vulnerabilities, or Snyk, are beginning to be incorporated, but these checks are implemented inconsistently and siloed.
⚠ Redundant exposure: Teams operating independently and relying on public registries like npm or PyPI lack shared, standardized systems for tracking packages in use. Exposure is amplified, the lack of visibility meaning multiple teams will likely adopt the same vulnerable packages, increasing the risks of security vulnerabilities in production, and extensive remediation costs when these risks are fixed multiple times between siloed teams.
⚠ Delayed remediation: Security risks are detected late, during CI/CD or post-deployment, because vulnerability scanning isn’t integrated at the package pulling stage. Fixes are reactive and handled one-off by individual teams, leading to slower patch cycles and prolonged risk exposure, while fixes incur high remediation costs.
⚠ Shadow risk: Some teams implement tools like Snyk or OWASP Dependency-Check, but usage is based on individual initiative, with no enforced policies to block risky packages. This results in flagged vulnerabilities winding up in production, undermining trust in the supply chain and teammates, and leading to informal developer workarounds, which serve only to further perpetuate decentralization and security risks.
⚠ Compliance challenges: Packages are pulled directly from public sources without formal license checks, with no organizational approval flow to approve or restrict certain licenses. Incompatible licenses (e.g., GPL, AGPL) are pulled, resulting in non-compliance and the risk of costly legal exposure and audit failures.
⚠ Scaling bottlenecks: Security responsibility is distributed but uncoordinated, with each team handling their own tools, standards, and alerts in isolation, resulting in duplicated effort, the development hours lost per team adding up quickly across the org, and seen in late product deliveries.
Inconsistent practices and no transparency render the organization’s security posture fragile, with critical package vulnerabilities and non-compliant licenses slipping into production, resulting in reactive responses that often incur expensive remediation costs.
Governance: Team-Level Rules Without Central Enforcement
Governance mechanisms are beginning to appear, often in the form of team-specific policies or localized CI/CD workflows, but org-wide, and even within individual teams, informality means they remain unenforced.
⚠ Shadow IT: Teams independently adopt OSS tools, libraries, and registries without cross-team alignment or formal approval processes. This freedom accelerates team-localized delivery, but overall leads to unmanaged tool sprawl, where proprietary packages shared between teams can’t be adopted easily, due to the platform configuration required.
⚠ Policy drift: Package governance is left to individual teams, with no organization-wide rules for usage, approval, or restrictions. Some teams create their own guidelines or ‘allow lists,’ while others rely on intuition or external defaults, eroding trust in proprietary packages and the CI/CD pipeline, and making scaling difficult.
⚠ Unscalable enforcement: There’s no central inventory or metadata for used packages across environments. Even if teams use basic tools like GitHub Packages or homegrown registries for publishing, there’s rarely a unified view across registries or a way to query dependencies org-wide, making it difficult to enforce or even prove compliance, leading to not only slower development, but longer exposure to security and compliance risks. This leads to slower development and prolonged exposure to security and compliance risks.
⚠ Audit blind spots: Package adoption decisions are usually made in code reviews, message threads, or by copying Stack Overflow examples, with no documentation or audit trail. If a vulnerable dependency is detected, it’s unclear who introduced it or what due diligence was performed (if any), both increasing the costs of and lengthening the remediation process.
⚠ Governance won’t scale: As more teams start building and consuming internal packages (via multiple team-specific registries hosted on Nexus, GitHub Packages, or S3 buckets), there’s no scalable way to manage naming conventions, versioning rules, or deprecation. Retroactive enforcement leads to slower development and higher costs.
These practices lead to an uneven and unreliable governance model that fails to provide adequate oversight or accountability as teams scale.
Auditability: Siloed Logging Undermines Organizational Visibility
Auditability begins to emerge through team-specific tools and pipelines, but the lack of centralization and standardization limits visibility across the organization.
⚠ Delayed incident response: Teams rely on scattered logs, like GitHub Actions, Jenkins builds, or Terraform pipelines, to manually trace vulnerability origins. For example, when Log4j vulnerabilities hit, teams trawl through logs or registry metadata, delaying incident response and prolonging exposure to untraceable vulnerabilities, even when teams are aware of them.
⚠ Opaque provenance and approval trails: Internal packages may be published to GitHub Packages or private PyPI mirrors, but there’s no enforced documentation for who created or approved them. When a questionable dependency appears, it’s nearly impossible to trace who added it, when, or why, so orgs cannot verify the integrity of their audits, or ensure compliance with risky licenses.
⚠ Inconsistent tracking: Some projects record package versions in package-lock.json or requirements.txt, others don’t, and even when they do, there’s no central place to query or analyze this data across teams, making simple questions like “Which services depend on lodash <4.17.21?” difficult to answer and wasting development time and resources.
⚠ Manual compliance verification: License compliance is largely reactive, with legal teams and auditors combing through individual repos or relying on last-minute Snyk exports. Without centralized evidence or usage tracking, demonstrating compliance (e.g., no GPL used) becomes time-consuming and error-prone, reducing the credibility of your audits.
⚠ Package origin and risk blind spots: Packages may come from public registries, GitHub forks, or coworker-published private feeds, yet they’re treated the same by most systems. Without tooling like Sigstore, in-toto, or curated mirrors (e.g., Proget), it’s difficult to verify a package’s origin and security, eroding developer trust in the CI/CD pipeline.
⚠ Security signals are siloed: Tools like npm audit, trivy, or safety surface vulnerabilities, but each runs in isolation, with no aggregation across environments and teams. This leads to missed insights and repeated mistakes, since a vulnerability remediated in one repository can remain in another, meaning the org remains exposed to security vulnerabilities that were thought to have been remediated.
Real-time incident response and long-term compliance are undermined due to the scattered and incomplete picture of package activity, both within the team level, and across the organization as a whole.
Scalability Readiness: Uncoordinated Package Practices Strain Growth
Internal tooling and package feeds are relied upon heavily within teams, but the absence of coordinated standards across the entire organization creates major friction as it grows.
⚠ CI/CD complexity increases: Teams use varied tools–GitLab CI, TeamCity, Jenkins–without alignment on how packages are pulled, validated, or promoted. Pipeline logic must be customized per team or repo, making automation difficult, and increasing onboarding time, as engineering teams spend more time maintaining pipelines than delivering features, leading to overall slower production releases.
⚠ Environment drift and version fragmentation: Internal packages are duplicated across Verdaccio, ProGet, Artifactory, and local dev machines, often with mismatched or conflicting versions. Without centralized coordination, compatibility breaks emerge silently and become difficult to trace and fix, prolonging downtime, development time, and resulting in late deliveries.
⚠ Operational friction multiplies: Registries, feeds, and storage backends differ between teams, requiring manual setup and troubleshooting when packages go missing or versions don’t match. This makes builds unpredictable, support difficult, and debugging slower.
⚠ Duplication of effort worsens: Common utilities (e.g., shared config loaders and internal SDKs) are rewritten by different teams because discovery is informal trust in other team’s artifacts is low. Even when the same solution exists elsewhere, a lack of documentation discourages reuse, leaving teams with developers who don’t trust existing functionality, instead rebuilding it at the cost of organizational resources.
⚠ Scaling exacerbates governance gaps: Security, compliance, and quality checks are hard to implement retroactively when every team has chosen their own tooling, registry setup, and publishing process, so rolling out org-wide standards requires entire infrastructure overhauls and team-by-team negotiation (which is difficult to uncoordinated communication).
⚠ Platform engineering blocked by inconsistency: Attempts to introduce golden paths, internal development problems (IDPs), or shared CI/CD templates hit a wall when foundational assumptions differ between teams, meaning platform engineers can’t offer one-size-fits-all solutions without significant rework and considerable resource drain.

These disconnected practices make it increasingly difficult to scale reliably, especially as more teams, languages, and workflows are introduced. Without centralized practices and infrastructure, each new team adds to the growing inconsistency, fueling inefficiency and risk instead of helping to accelerate growth.
Moving Forward: Advancing Beyond Ad-Hoc Progress with Unified Standards
At Level 2, many organizations make valuable progress by spinning up internal package registries and introducing localized tools. But these improvements often remain siloed, limited to individual teams, stacks, or workflows, with no broader consistency, oversight, or shared benefit. As a result, friction persists, visibility is uneven, and duplication and risk remain common.
To break through this plateau, teams need more than incremental improvements. The real unlock comes from consolidating efforts across teams, aligning on shared policies, and investing in platform-wide visibility, governance, and scalability.
✅ Centralization: Multiple isolated registries, like Verdacccio, GitHub Packages, or PyPI Server, fragment the developer experience and slow package reuse. By consolidating into a unified, organization-wide registry such as ProGet, teams gain a single, trusted source for publishing and consuming packages, regardless of language or tech stack.
Why this helps: Centralization reduces confusion, encourages reuse, and provides a clear backbone for standardized development workflows, boosting collaboration and delivery velocity across the org.
✅ Governance: Inconsistent, team-level polices leave wide gaps in oversight and compliance. Implementing organization-wide role-based access controls, promotion workflows, and retention policies allows organizations to introduce consistent standards for package publishing, approvals, and cleanup, without disrupting local team autonomy.
Why this helps: Centralized governance prevents shadow IT, reduces compliance risk, and ensures development efforts align with legal, security, and organizational standards, without slowing down development.
✅ Curation: Many Level 2 organizations adopt tools like Snyk, OWASP Dependency-Check, or Trivy, but use them reactively, alerting on vulnerabilities after packages are already in use. What’s often missing is a preventative approach to supply chain risk: curated feeds, pre-approval workflows, and org-wide policies that control what can enter the ecosystem in the first place. Enterprise-grade tooling with integrated scanning and enforcement moves security earlier in the process.
Why this helps: Curation ensures the security of your software supply chain by enabling intentional, reviewed adoption, preventing last-minute surprises, and long-term exposure.
✅ Distribution and Visibility: When registries, logs, and vulnerability data live in team silos, it’s nearly impossible to understand how packages flow across environments. Centralizing metadata, approvals, and usage tracking provides visibility into what packages exist, where they’re used, and how they were approved.
Why this helps: Distribution visibility turns reactive firefighting into proactive risk management, empowering faster incident response, stronger audit confidence, and better strategic decision making.
✅ Scalability: As more teams build their own workflows, technical debt compounds and platform fragmentation grows. Mutli-feed support and CI/CD integrations enable teams to scale package workflows in a standardized, maintainable way.
Why this helps: Investing in scalable infrastructure early allows you to support more teams, languages, and services, without losing control or slowing down delivery.
By moving directly from Level 2 to Level 4 or 5, organizations avoid getting stuck in a cycle of local optimizations that don’t translate to lasting impact. The shift to centralized, policy-driven, and insight-rich package management unlocks not only faster, more confident development, but also a foundation for platform engineering, supply chain security, and long-term organizational scale.
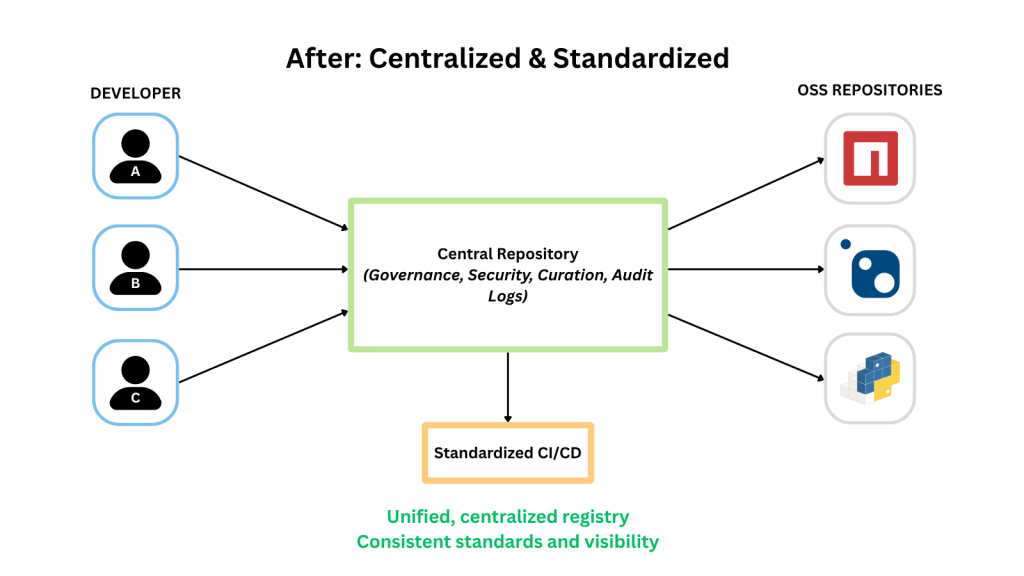
Enterprise-grade tools like ProGet help bridge that gap, transforming fragmented tooling and team-level wins into strategic, organization-wide capability that accelerates every stage of software delivery.
Does This Sound Like Your Organization? Assess Your Package Maturity and Plan Your Next Move
Evaluating your package management maturity internally can be tricky. It’s easy to overlook blind spots, make assumptions, or lack the benchmarks needed for a clear view. That’s why we recommend a guided assessment with our team. Our experts bring experience across industries, helping you identify risks and opportunities that internal reviews may miss.
You can schedule your assessment directly from our homepage:
Your assessment report will show where you stand in our maturity model, providing both a strategic overview and detailed, level-specific guidance for actionable next steps.
If you haven’t already, why not take a look at the guide this article came from, Package Management at Scale. It offers early access to upcoming articles, deep dives on centralization, distribution, and curation, plus a practical rubric for evaluating your team’s maturity. Download your copy today!
